
The one-sentence idea: A language model (the “LM” in LLM) is like a very smart autocomplete. You start a sentence, and it guesses what comes next—one tiny piece at a time—over and over, incredibly fast.
1) Text gets broken into tiny pieces
Computers don’t handle whole words the way we do. They slice text into small chunks called tokens (little bits of words and punctuation). Think of tokens as puzzle pieces. To “talk,” the model picks the next puzzle piece, adds it to the line, then picks the next one.
“The cat sat on the ____” → it chooses “mat”. Then it keeps going: “on the mat and…”
2) How it learned: a long reading marathon
Before you ever chat with it, the model goes through training. During training it reads a huge amount of text. Its job is always the same: look at some tokens and guess the next token. If the guess is wrong, the model tweaks its internal settings so the next guess is a little better.
Those internal settings are called weights or parameters. Imagine billions of tiny dials being nudged left or right. Over many, many guesses, the model gets good at patterns: grammar, common facts it saw, styles of writing, and how sentences usually flow.
3) What’s inside: lots of small helpers
Inside the model are many simple parts (often called “neurons”). Each notices small things—maybe that a sentence looks like a question, or that the next token should probably be a number, or that a name usually follows the word “Dr.” By themselves they’re simple; together they make strong predictions.
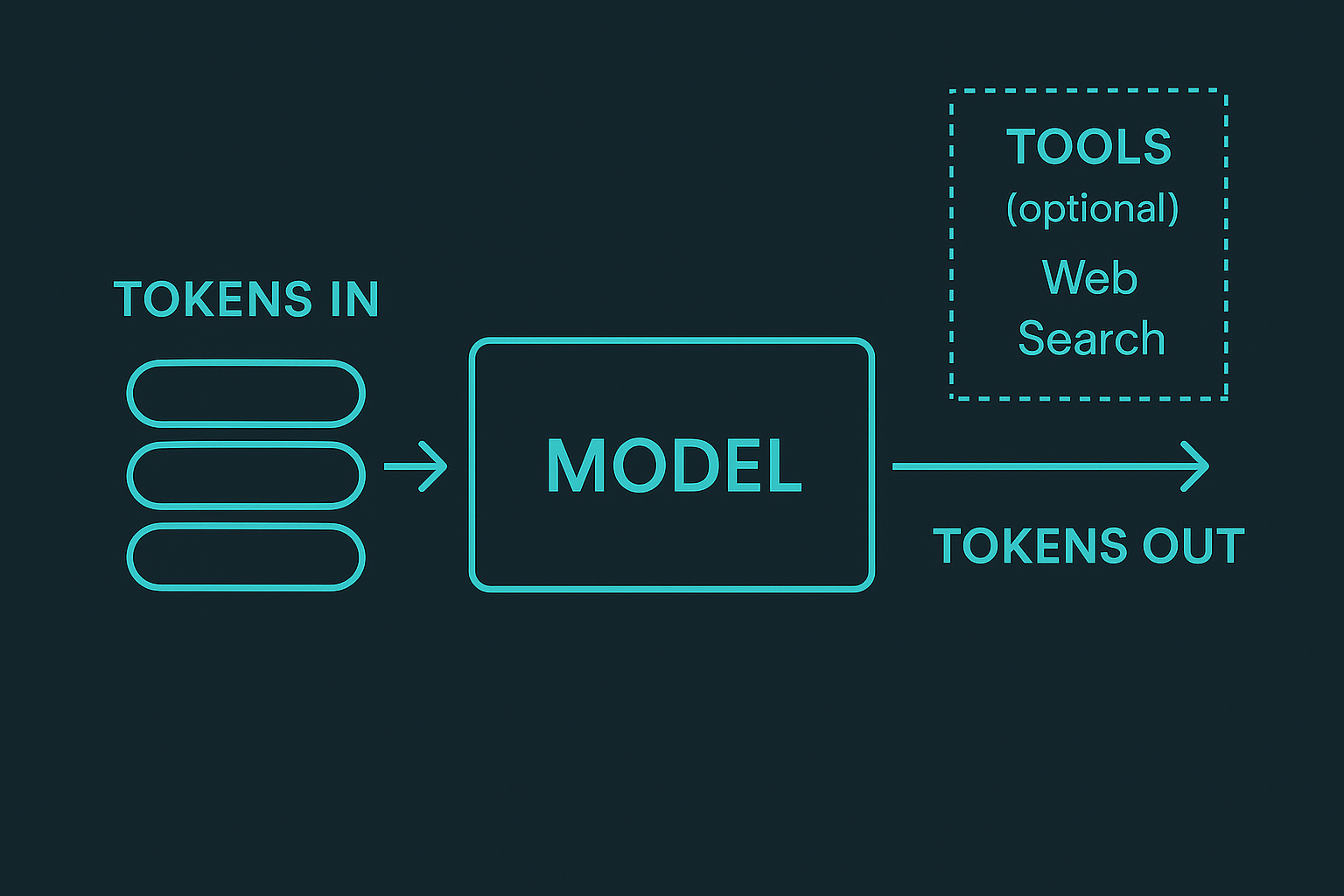
4) What happens when you type
- You write a prompt: “Tell me a quick story about a brave kite.”
- The model checks everything in the conversation so far (your message + recent history).
- It asks itself, “Based on what I’ve learned, what’s the most likely next token?”
- It outputs that token, adds it to the text, and repeats the process for the next token… and the next.
This step-by-step choosing is called inference. Training is learning; inference is using what it learned.
5) Short-term memory: the “context window”
The model doesn’t remember everything forever. It has a limited “whiteboard” called a context window. If the conversation gets longer than that window, older parts fall off the back. Bigger models often have bigger windows, but they’re still not limitless.
6) Why it sometimes gets things wrong
- It predicts, it doesn’t know. The model is guessing the next token from patterns. If the prompt is unclear or the pattern is weak, it can sound confident and still be wrong (people call this “hallucination”).
- It doesn’t browse unless you let it. A base model doesn’t search the web by itself. If a system adds web search or tools, that’s extra capability wrapped around the model.
- Context limits. If key details scrolled out of the window, the model can lose the thread.
7) How we steer the style
- System instructions: A hidden “first message” that sets the role and tone (e.g., “be concise and helpful”).
- Temperature: A creativity knob. Lower = safer and more predictable. Higher = more varied and imaginative.
- Examples: Showing a few sample Q&As teaches the model the format you want right now.
8) What LLMs are great at
- Summarizing and explaining: Shrinking long text and clarifying ideas.
- Rewriting and translating: Changing tone, fixing grammar, moving between languages.
- Structuring info: Turning messy notes into lists, tables, or checklists.
- Light reasoning: Step-by-step planning, comparisons, and pros/cons.
For live facts, private data, or actions on your computer, an LLM needs tools (like web search, a calendar, or a file reader). The model decides when to call a tool; the tool does the real work; the results come back into the conversation.
9) Local vs. cloud (why we care)
Many models can run right on your laptop or desktop. Local models are fast, private, and available offline; cloud models are great for heavier jobs or big shared knowledge. Our philosophy: run locally by default, use the network only when it clearly helps—and say so when we do.
10) A tiny glossary
- LLM: “Large Language Model.” A program that predicts the next token of text.
- Token: A small piece of text (part of a word, a whole word, or punctuation).
- Training: The long learning phase where the model reads text and adjusts its internal “dials.”
- Inference: Using the trained model to produce answers now.
- Parameters/weights: The billions of tiny settings the model adjusts during training.
- Context window: The amount of text the model can “see” at once.
- Temperature: A knob to make answers more predictable (low) or more creative (high).
TL;DR
- An LLM is super-powered autocomplete.
- It learned by guessing the next token millions of times and adjusting itself.
- When you chat, it picks one token after another to form a reply.
- It has a limited short-term memory (context window).
- It doesn’t browse or act unless a tool is connected.
- Local models give speed and privacy; cloud helps for bigger shared tasks.
That’s the whole picture. Simple ideas, stacked together, make surprisingly useful assistants.